Multimodal AI Needs More Than Modality Support: Researchers Propose General-Level and General-Bench to Evaluate True Synergy in Generalist Models


Artificial intelligence has grown beyond language-focused systems, evolving into models capable of processing multiple input types, such as text, images, audio, and video. This area, known as multimodal learning, aims to replicate the natural human ability to integrate and interpret varied sensory data. Unlike conventional AI models that handle a single modality, multimodal generalists are designed to process and respond across formats. The goal is to move closer to creating systems that mimic human cognition by seamlessly combining different types of knowledge and perception.
The challenge faced in this field lies in enabling these multimodal systems to demonstrate true generalization. While many models can process multiple inputs, they often fail to transfer learning across tasks or modalities. This absence of cross-task enhancement—known as synergy—hinders progress toward more intelligent and adaptive systems. A model may excel in image classification and text generation separately, but it cannot be considered a robust generalist without the ability to connect skills from both domains. Achieving this synergy is essential for developing more capable, autonomous AI systems.
Many current tools rely heavily on large language models (LLMs) at their core. These LLMs are often supplemented with external, specialized components tailored to image recognition or speech analysis tasks. For example, existing models such as CLIP or Flamingo integrate language with vision but do not deeply connect the two. Instead of functioning as a unified system, they depend on loosely coupled modules that mimic multimodal intelligence. This fragmented approach means the models lack the internal architecture necessary for meaningful cross-modal learning, resulting in isolated task performance rather than holistic understanding.
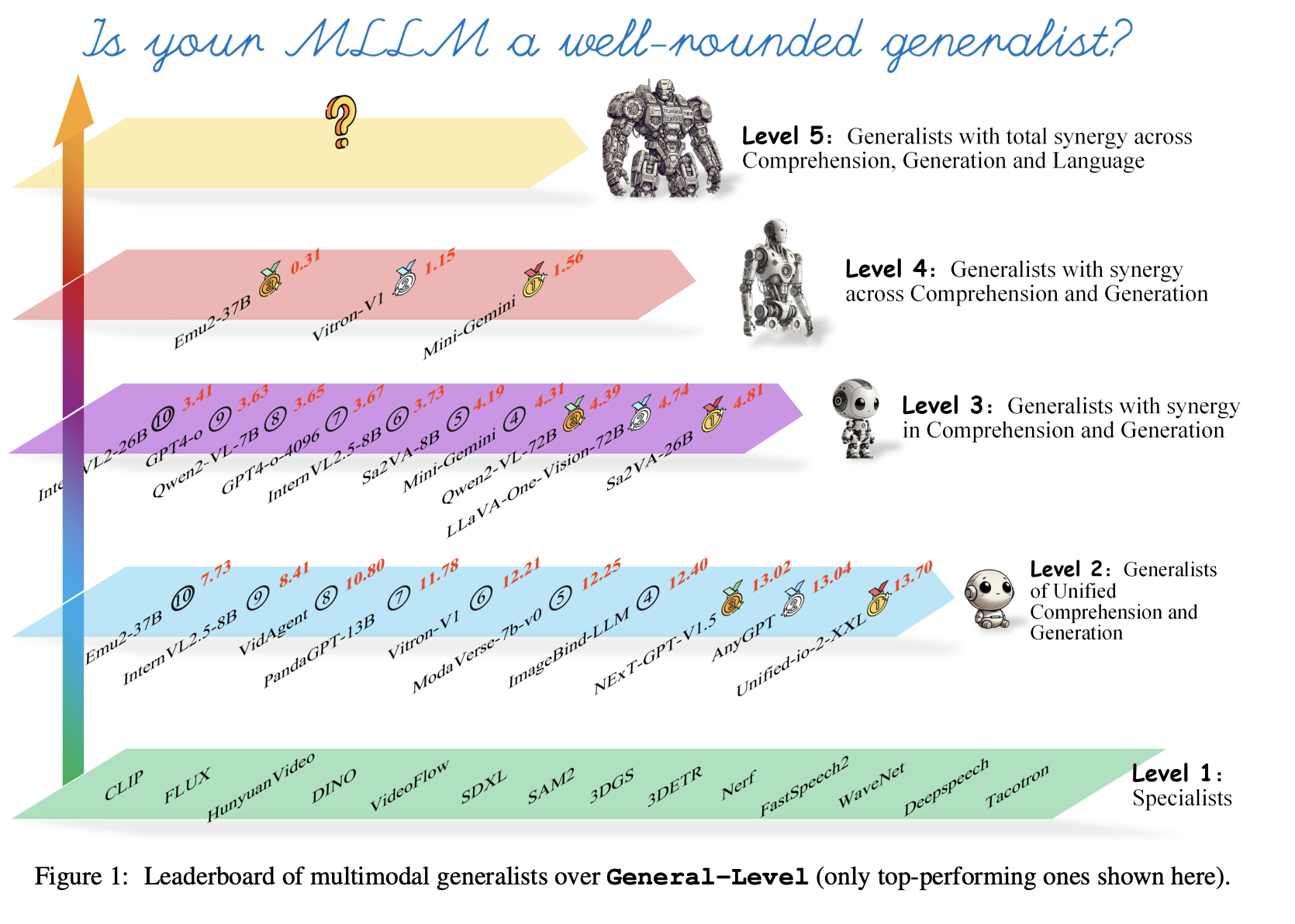
Researchers from the National University of Singapore (NUS), Nanyang Technological University (NTU), Zhejiang University (ZJU), Peking University (PKU), and others proposed an AI framework named General-Level and a benchmark called General-Bench. These tools are built to measure and promote synergy across modalities and tasks. General-Level establishes five levels of classification based on how well a model integrates comprehension, generation, and language tasks. The benchmark is supported by General-Bench, a large dataset encompassing over 700 tasks and 325,800 annotated examples drawn from text, images, audio, video, and 3D data.

The evaluation method within General-Level is built on the concept of synergy. Models are assessed by task performance and their ability to exceed state-of-the-art (SoTA) specialist scores using shared knowledge. The researchers define three types of synergy—task-to-task, comprehension-generation, and modality-modality—and require increasing capability at each level. For example, a Level-2 model supports many modalities and tasks, while a Level-4 model must exhibit synergy between comprehension and generation. Scores are weighted to reduce bias from modality dominance and encourage models to support a balanced range of tasks.
The researchers tested 172 large models, including over 100 top-performing MLLMs, against General-Bench. Results revealed that most models do not demonstrate the needed synergy to qualify as higher-level generalists. Even advanced models like GPT-4V and GPT-4o did not reach Level 5, which requires models to use non-language inputs to improve language understanding. The highest-performing models managed only basic multimodal interactions, and none showed evidence of total synergy across tasks and modalities. For instance, the benchmark showed 702 tasks assessed across 145 skills, yet no model achieved dominance in all areas. General-Bench’s coverage across 29 disciplines, using 58 evaluation metrics, set a new standard for comprehensiveness.

This research clarifies the gap between current multimodal systems and the ideal generalist model. The researchers address a core issue in multimodal AI by introducing tools prioritizing integration over specialization. With General-Level and General-Bench, they offer a rigorous path forward for assessing and building models that handle various inputs and learn and reason across them. Their approach helps steer the field toward more intelligent systems with real-world flexibility and cross-modal understanding.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 90k+ ML SubReddit.
Here’s a brief overview of what we’re building at Marktechpost:
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
