A Coding Guide to Build an Optical Character Recognition (OCR) App in Google Colab Using OpenCV and Tesseract-OCR


Optical Character Recognition (OCR) is a powerful technology that converts images of text into machine-readable content. With the growing need for automation in data extraction, OCR tools have become an essential part of many applications, from digitizing documents to extracting information from scanned images. In this tutorial, we will build an OCR app that runs effortlessly on Google Colab, leveraging tools like OpenCV for image processing, Tesseract-OCR for text recognition, NumPy for array manipulations, and Matplotlib for visualization. By the end of this guide, you can upload an image, preprocess it, extract text, and download the results, all within a Colab notebook.
!pip install pytesseract opencv-python numpy matplotlib
To set up the OCR environment in Google Colab, we first install Tesseract-OCR, an open-source text recognition engine, using apt-get. Also, we install essential Python libraries like pytesseract (for interfacing with Tesseract), OpenCV (for image processing), NumPy (for numerical operations), and Matplotlib (for visualization).
import pytesseract
import numpy as np
import matplotlib.pyplot as plt
from google.colab import files
from PIL import Image
Next, we import the necessary libraries for image processing and OCR tasks. OpenCV (cv2) is used for reading and preprocessing images, while pytesseract provides an interface to the Tesseract OCR engine for text extraction. NumPy (np) helps with array manipulations, and Matplotlib (plt) visualizes processed images. Google Colab’s files module allows users to upload images, and PIL (Image) facilitates image conversions required for OCR processing.
filename = list(uploaded.keys())[0]
To process an image for OCR, we first need to upload it to Google Colab. The files.upload() function from Google Colab’s files module enables users to select and upload an image file from their local system. The uploaded file is stored in a dictionary, with the filename as the key. We extract the filename using list(uploaded.keys())[0], which allows us to access and process the uploaded image in the subsequent steps.
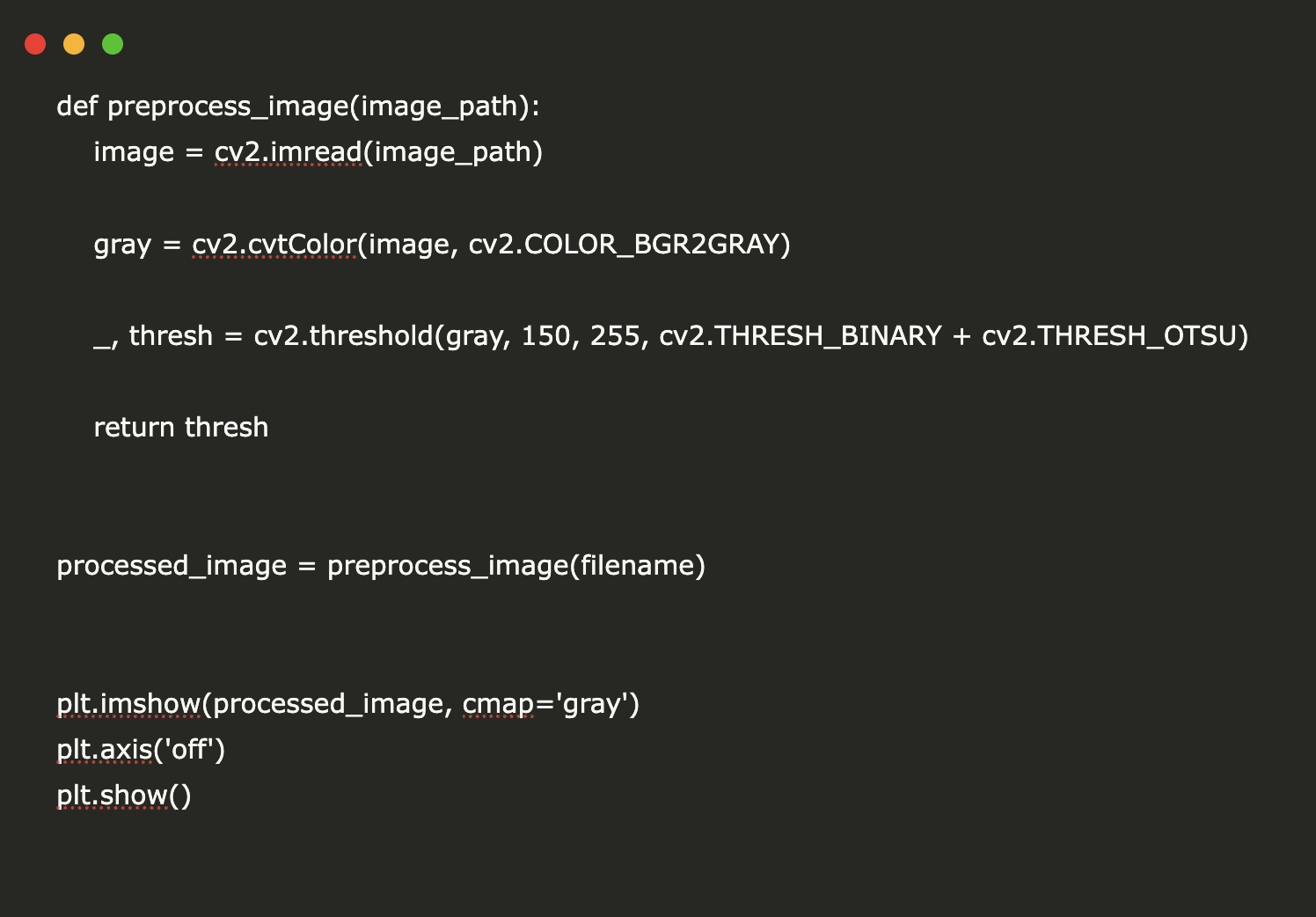
image = cv2.imread(image_path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
return thresh
processed_image = preprocess_image(filename)
plt.imshow(processed_image, cmap=’gray’)
plt.axis(‘off’)
plt.show()
To improve OCR accuracy, we apply a preprocessing function that enhances image quality for text extraction. The preprocess_image() function first reads the uploaded image using OpenCV (cv2.imread()) and converts it to grayscale using cv2.cvtColor(), as grayscale images are more effective for OCR. Next, we apply binary thresholding with Otsu’s method using cv2.threshold(), which helps distinguish text from the background by converting the image into a high-contrast black-and-white format. Finally, the processed image is displayed using Matplotlib (plt.imshow()).
pil_image = Image.fromarray(image)
text = pytesseract.image_to_string(pil_image)
return text
extracted_text = extract_text(processed_image)
print(“Extracted Text:”)
print(extracted_text)
The extract_text() function performs OCR on the preprocessed image. Since Tesseract-OCR requires a PIL image format, we first convert the NumPy array (processed image) into a PIL image using Image.fromarray(image). Then, we pass this image to pytesseract.image_to_string(), which extracts and returns the detected text. Finally, the extracted text is printed, showcasing the OCR result from the uploaded image.
f.write(extracted_text)
files.download(“extracted_text.txt”)
To ensure the extracted text is easily accessible, we save it as a text file using Python’s built-in file handling. The open(“extracted_text.txt”, “w”) command creates (or overwrites) a text file and writes the extracted OCR output into it. After saving the file, we use files.download(“extracted_text.txt”) to provide an automatic download link.
In conclusion, by integrating OpenCV, Tesseract-OCR, NumPy, and Matplotlib, we have successfully built an OCR application that can process images and extract text in Google Colab. This workflow provides a simple yet effective way to convert scanned documents, printed text, or handwritten content into digital text format. The preprocessing steps ensure better accuracy, and the ability to save and download results makes it convenient for further analysis.
Here is the Colab Notebook. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 80k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
