Efficient Inference-Time Scaling for Flow Models: Enhancing Sampling Diversity and Compute Allocation


Recent advancements in AI scaling laws have shifted from merely increasing model size and training data to optimizing inference-time computation. This approach, exemplified by models like OpenAI o1 and DeepSeek R1, enhances model performance by leveraging additional computational resources during inference. Test-time budget forcing has emerged as an efficient technique in LLMs, enabling improved performance with minimal token sampling. Similarly, inference-time scaling has gained traction in diffusion models, particularly in reward-based sampling, where iterative refinement helps generate outputs that better align with user preferences. This method is crucial for text-to-image generation, where naïve sampling often fails to fully capture intricate specifications, such as object relationships and logical constraints.
Inference-time scaling methods for diffusion models can be broadly categorized into fine-tuning-based and particle-sampling approaches. Fine-tuning improves model alignment with specific tasks but requires retraining for each use case, limiting scalability. In contrast, particle sampling—used in techniques like SVDD and CoDe—selects high-reward samples iteratively during denoising, significantly improving output quality. While these methods have been effective for diffusion models, their application to flow models has been limited due to the deterministic nature of their generation process. Recent work, including SoP, has introduced stochasticity to flow models, enabling particle sampling-based inference-time scaling. This study expands on such efforts by modifying the reverse kernel, further enhancing sampling diversity and effectiveness in flow-based generative models.
Researchers from KAIST propose an inference-time scaling method for pretrained flow models, addressing their limitations in particle sampling due to a deterministic generative process. They introduce three key innovations: (1) SDE-based generation to enable stochastic sampling, (2) VP interpolant conversion to enhance sample diversity, and (3) Rollover Budget Forcing (RBF) for adaptive computational resource allocation. Experimental results show that these techniques improve reward alignment in tasks like compositional text-to-image generation. Their approach outperforms prior methods, demonstrating the advantages of inference-time scaling in flow models, particularly when combined with gradient-based techniques for differentiable rewards like aesthetic image generation.
Inference-time reward alignment aims to generate high-reward samples from a pretrained flow model without retraining. The objective is to maximize the expected reward while minimizing deviation from the original data distribution using KL regularization. Since direct sampling is challenging, particle sampling techniques, commonly used in diffusion models, are adapted. However, flow models rely on deterministic sampling, limiting exploration. To address this, inference-time stochastic sampling is introduced by converting deterministic processes into stochastic ones. Additionally, interpolant conversion enhances search space by aligning flow model sampling with diffusion models. A dynamic compute allocation strategy further optimizes efficiency during inference-time scaling.
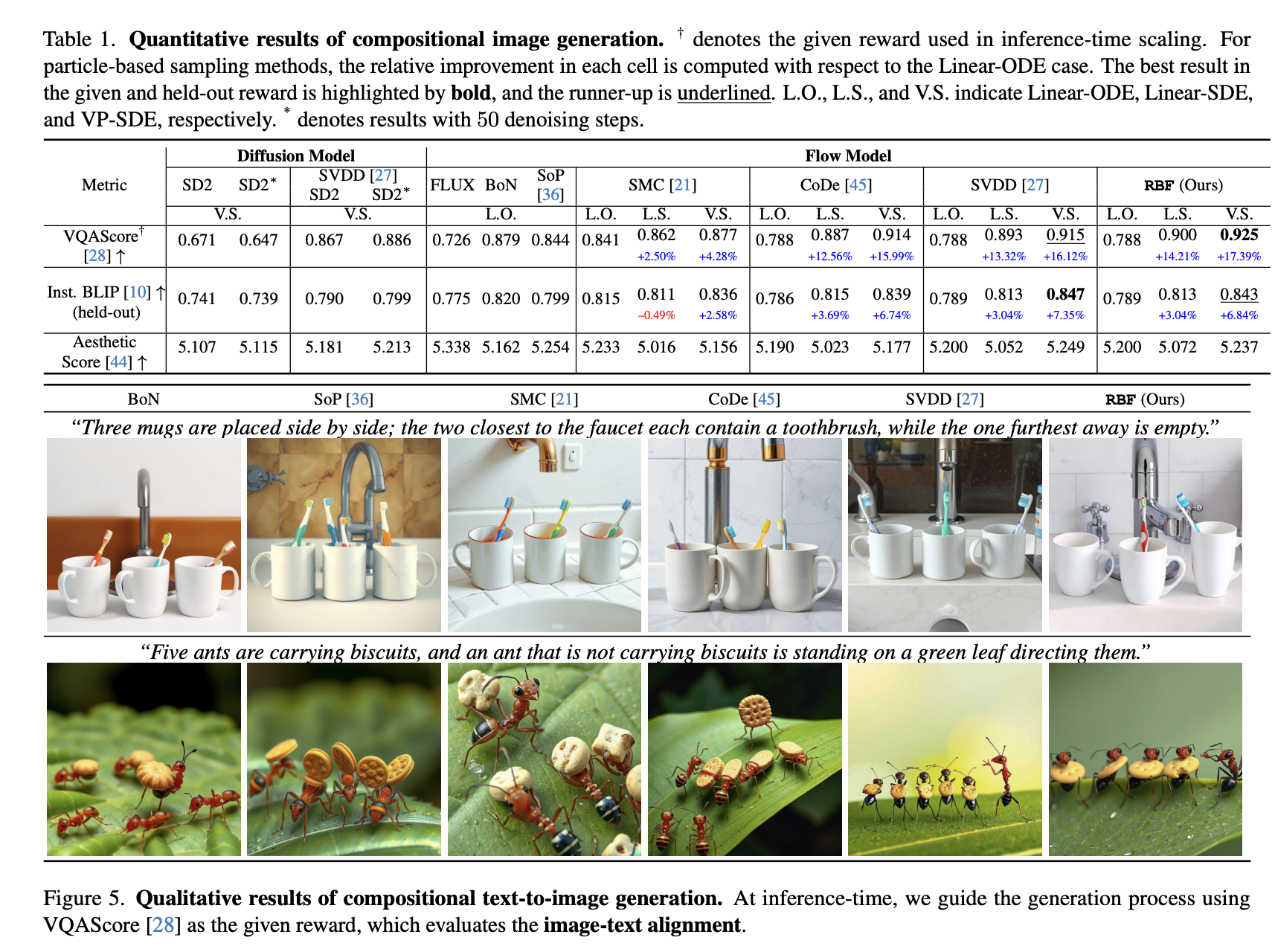
The study presents experimental results on particle sampling methods for inference-time reward alignment. The study focuses on compositional text-to-image and quantity-aware image generation, using FLUX as the pretrained flow model. Metrics such as VQAScore and RSS assess alignment and accuracy. Results indicate that inference-time stochastic sampling improves efficiency, with interpolant conversion further enhancing performance. Flow-based particle sampling yields high-reward outputs compared to diffusion models without compromising image quality. The proposed RBF method optimizes budget allocation, achieving the best reward alignment and accuracy results. Qualitative and quantitative findings confirm its effectiveness in generating precise, high-quality images.
In conclusion, the study introduces an inference-time scaling method for flow models, incorporating three key innovations: (1) ODE-to-SDE conversion for enabling particle sampling, (2) linear-to-VP interpolant conversion to enhance diversity and search efficiency, and (3) RBF for adaptive compute allocation. While diffusion models benefit from stochastic sampling during denoising, flow models require tailored approaches due to their deterministic nature. The proposed VP-SDE-based generation effectively integrates particle sampling, and RBF optimizes compute usage. Experimental results demonstrate that this method surpasses existing inference-time scaling techniques, improving performance while maintaining high-quality outputs in flow-based image and video generation models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
