


In brief
- Google’s new Gemini 2.5 Pro tops the WebDev Arena leaderboard, outperforming competitors like Claude in coding tasks, making it a standout choice for developers seeking superior coding capabilities.
- The AI model also features a 1 million token context window (expandable to 2 million), enabling it to handle large codebases and complex projects far beyond the capacity of models like ChatGPT and Claude 3.7 Sonnet.
- It also achieved the highest scores on reasoning benchmarks, including a MENSA IQ test and Humanity’s Last Exam, demonstrating advanced problem-solving skills essential for sophisticated development tasks.
Google’s recently launched Gemini 2.5 Pro has risen to the top spot on coding leaderboards, beating Claude in the famous WebDev Arena—a non-denominational ranking site akin to the LLM arena, but focused specifically on measuring how good AI models are at coding. The achievement comes amid Google’s push to position its flagship AI model as a leader in both coding and reasoning tasks.
Released earlier this year Gemini 2.5 Pro ranks first across several categories, including coding, style control, and creative writing. The model’s massive context window—one million tokens expanding to two million soon—allows it to handle large codebases and complex projects that would choke even the closest competitors. For context, powerful models like ChatGPT and Claude 3.7 Sonnet can only handle up to 128K tokens.
Gemini also has the highest “IQ” of all AI models. TrackingAI put it through formalized MENSA tests, using verbalized questions from Mensa Norway to create a standardized way to compare AI models.
Gemini 2.5 Pro scored higher than competitors on these tests, even when using bespoke questions not publicly available in training data.
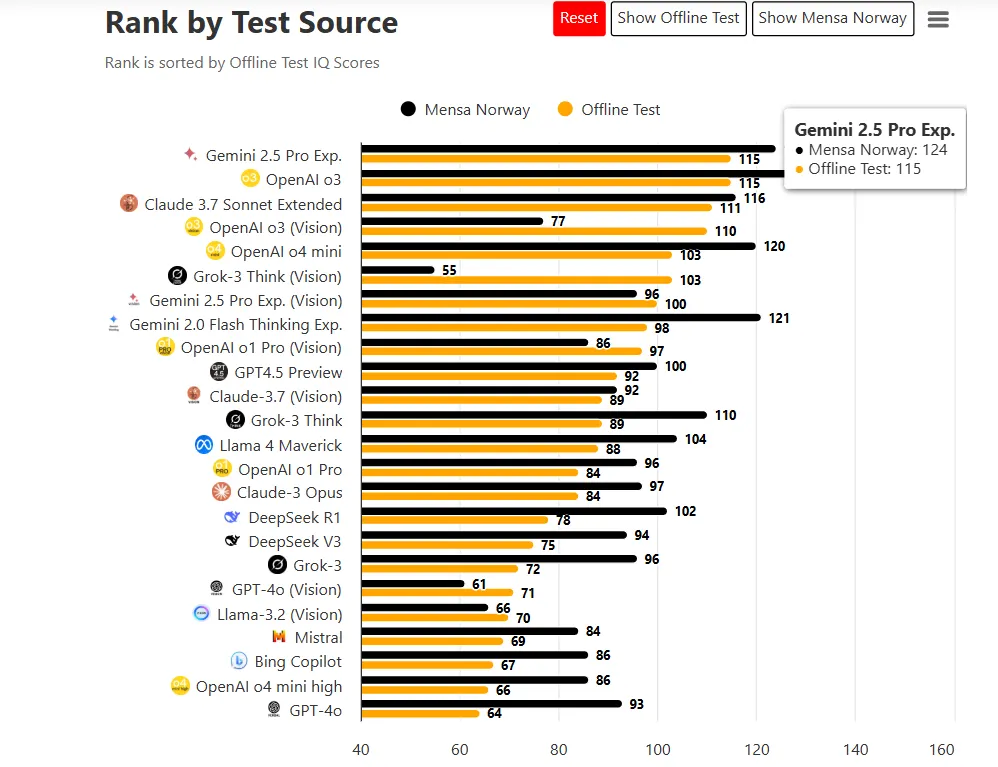
With an IQ score of 115 in offline tests, the new Gemini ranks among the “bright minded,” with the average human intelligence scoring around 85 to 114 points. But the notion of an AI having IQ needs unpacking. AI systems don’t have intelligence quotients like humans do, so it’s better to think of the benchmark as a metaphor for performance on reasoning benchmarks.
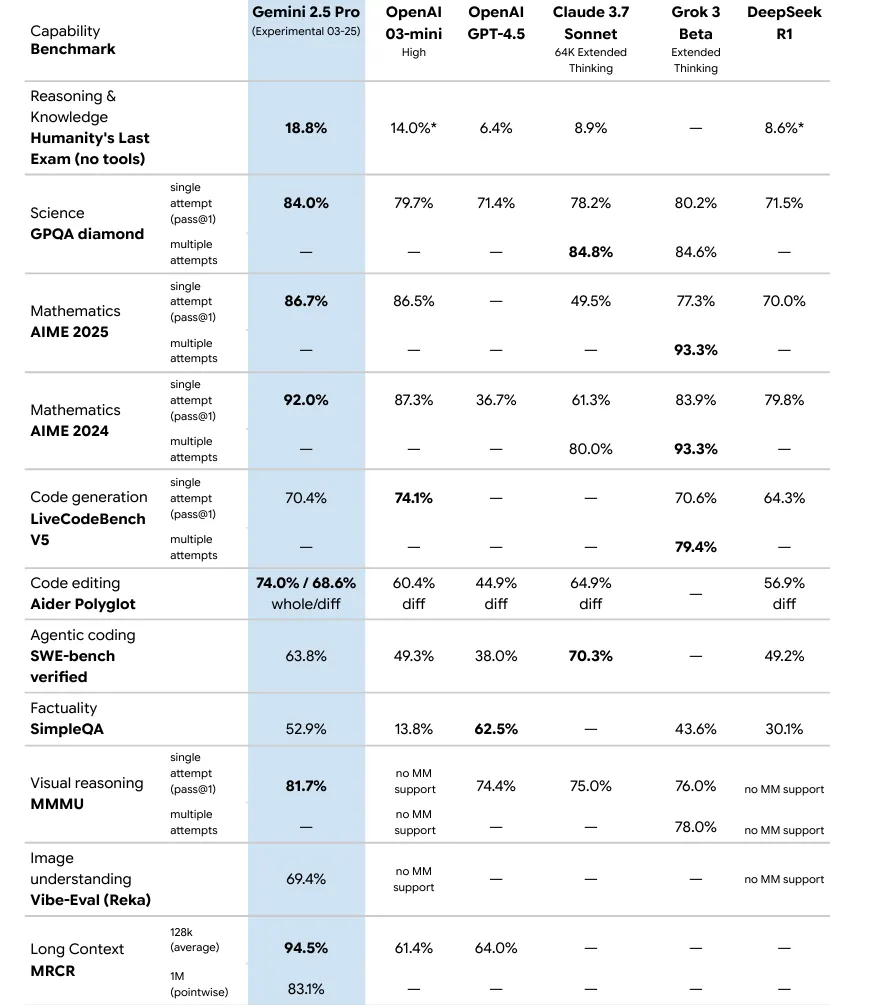
For benchmarks specifically designed for AI, Gemini 2.5 Pro scored 86.7% on the AIME 2025 math test and 84.0% on the GPQA science assessment. On Humanity’s Last Exam (HLE), a newer and harder benchmark created to avoid test saturation problems, Gemini 2.5 scored 18.8%, beating OpenAI’s o3 mini (14%) and Claude 3.7 Sonnet (8.9%) which is remarkable in terms of the performance boost..
The new version of Gemini 2.5 Pro is now available for free (with rate limits) to all Gemini users. Google previously described this release as an “experimental version of 2.5 Pro,” part of its family of “thinking models” designed to reason through responses rather than simply generate text.
Despite not winning every benchmark, Gemini has caught developers’ attention with its versatility. The model can create complex applications from single prompts, building interactive web apps, endless runner games, and visual simulations without requiring detailed instructions.
We tested the model asking it to fix a broken HTML5 code. It generated almost 1000 lines of code, providing results that beat Claude 3.7 Sonnet—the previous leader—in terms of quality and understanding of the full set of instructions.
For working developers, Gemini 2.5 Pro’s input costs $2.50 per million tokens and output costs $15.00 per million tokens, positioning it as a cheaper alternative to some competitors while still offering impressive capabilities.
The AI model handles up to 30,000 lines of code in its Advanced plan, making it suitable for enterprise-level projects. Its multimodal abilities—working with text, code, audio, images, and video—add flexibility that other coding-focused models can’t match.
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.
