Highlighted at CVPR 2025: Google DeepMind’s ‘Motion Prompting’ Paper Unlocks Granular Video Control


Key Takeaways:
- Researchers from Google DeepMind, the University of Michigan & Brown university have developed “Motion Prompting,” a new method for controlling video generation using specific motion trajectories.
- The technique uses “motion prompts,” a flexible representation of movement that can be either sparse or dense, to guide a pre-trained video diffusion model.
- A key innovation is “motion prompt expansion,” which translates high-level user requests, like mouse drags, into detailed motion instructions for the model.
- This single, unified model can perform a wide array of tasks, including precise object and camera control, motion transfer from one video to another, and interactive image editing, without needing to be retrained for each specific capability.
As generative AI continues to evolve, gaining precise control over video creation is a critical hurdle for its widespread adoption in markets like advertising, filmmaking, and interactive entertainment. While text prompts have been the primary method of control, they often fall short in specifying the nuanced, dynamic movements that make video compelling. A new paper, presented and highlighted at CVPR 2025, from Google DeepMind, the University of Michigan, and Brown University introduces a groundbreaking solution called “Motion Prompting,” which offers an unprecedented level of control by allowing users to direct the action in a video using motion trajectories.
This new approach moves beyond the limitations of text, which struggles to describe complex movements accurately. For instance, a prompt like “a bear quickly turns its head” is open to countless interpretations. How fast is “quickly”? What is the exact path of the head’s movement? Motion Prompting addresses this by allowing creators to define the motion itself, opening the door for more expressive and intentional video content.
Introducing Motion Prompts
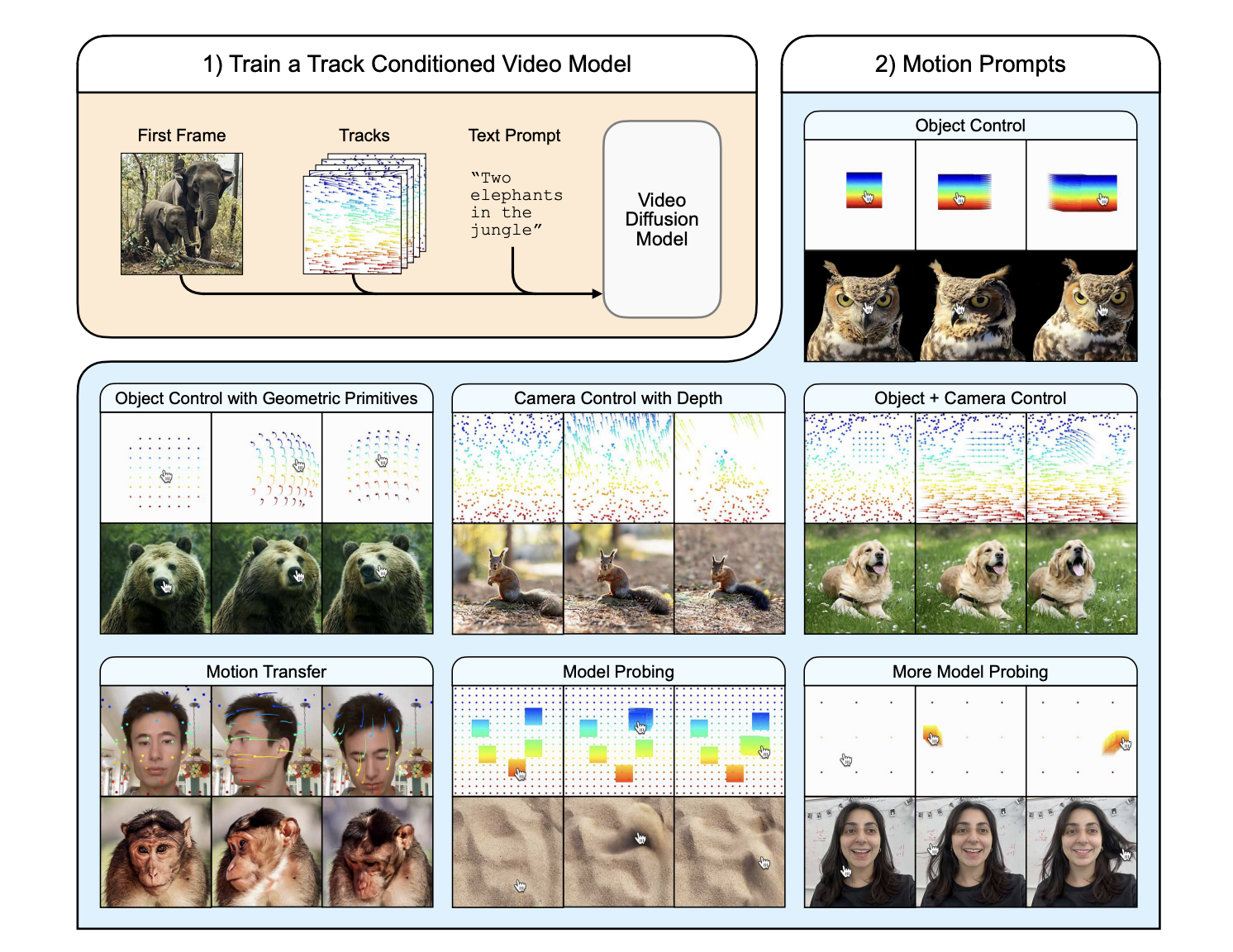
At the core of this research is the concept of a “motion prompt.” The researchers identified that spatio-temporally sparse or dense motion trajectories—essentially tracking the movement of points over time—are an ideal way to represent any kind of motion. This flexible format can capture anything from the subtle flutter of hair to complex camera movements.
To enable this, the team trained a ControlNet adapter on top of a powerful, pre-trained video diffusion model called Lumiere. The ControlNet was trained on a massive internal dataset of 2.2 million videos, each with detailed motion tracks extracted by an algorithm called BootsTAP. This diverse training allows the model to understand and generate a vast range of motions without specialized engineering for each task.

From Simple Clicks to Complex Scenes: Motion Prompt Expansion
While specifying every point of motion for a complex scene would be impractical for a user, the researchers developed a process they call “motion prompt expansion.” This clever system translates simple, high-level user inputs into the detailed, semi-dense motion prompts the model needs.
This allows for a variety of intuitive applications:
“Interacting” with an Image: A user can simply click and drag their mouse across an object in a still image to make it move. For example, a user could drag a parrot’s head to make it turn, or “play” with a person’s hair, and the model generates a realistic video of that action. Interestingly, this process revealed emergent behaviors, where the model would generate physically plausible motion, like sand realistically scattering when “pushed” by the cursor.


Object and Camera Control: By interpreting mouse movements as instructions to manipulate a geometric primitive (like an invisible sphere), users can achieve fine-grained control, such as precisely rotating a cat’s head. Similarly, the system can generate sophisticated camera movements, like orbiting a scene, by estimating the scene’s depth from the first frame and projecting a desired camera path onto it. The model can even combine these prompts to control an object and the camera simultaneously.

Motion Transfer: This technique allows the motion from a source video to be applied to a completely different subject in a static image. For instance, the researchers demonstrated transferring the head movements of a person onto a macaque, effectively “puppeteering” the animal.

Putting it to the Test
The team conducted extensive quantitative evaluations and human studies to validate their approach, comparing it against recent models like Image Conductor and DragAnything. In nearly all metrics, including image quality (PSNR, SSIM) and motion accuracy (EPE), their model outperformed the baselines.

A human study further confirmed these results. When asked to choose between videos generated by Motion Prompting and other methods, participants consistently preferred the results from the new model, citing better adherence to the motion commands, more realistic motion, and higher overall visual quality.
Limitations and Future Directions
The researchers are transparent about the system’s current limitations. Sometimes the model can produce unnatural results, like stretching an object unnaturally if parts of it are mistakenly “locked” to the background. However, they suggest that these very failures can be used as a valuable tool to probe the underlying video model and identify weaknesses in its “understanding” of the physical world.
This research represents a significant step toward creating truly interactive and controllable generative video models. By focusing on the fundamental element of motion, the team has unlocked a versatile and powerful tool that could one day become a standard for professionals and creatives looking to harness the full potential of AI in video production.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Jean-marc is a successful AI business executive .He leads and accelerates growth for AI powered solutions and started a computer vision company in 2006. He is a recognized speaker at AI conferences and has an MBA from Stanford.

