Microsoft AI Introduces Code Researcher: A Deep Research Agent for Large Systems Code and Commit History


Rise of Autonomous Coding Agents in System Software Debugging
The use of AI in software development has gained traction with the emergence of large language models (LLMs). These models are capable of performing coding-related tasks. This shift has led to the design of autonomous coding agents that assist or even automate tasks traditionally carried out by human developers. These agents range from simple script writers to complex systems capable of navigating codebases and diagnosing errors. Recently, the focus has shifted toward enabling these agents to handle more sophisticated challenges. Especially those associated with extensive and intricate software environments. This includes foundational systems software, where precise changes require understanding of not only the immediate code but also its architectural context, interdependencies, and historical evolution. Thus, there’s growing interest in building agents that can perform in-depth reasoning and synthesize fixes or changes with minimal human intervention.
Challenges in Debugging Large-Scale Systems Code
Updating large-scale systems code presents a multifaceted challenge due to its inherent size, complexity, and historical depth. These systems, such as operating systems and networking stacks, consist of thousands of interdependent files. They have been refined over decades by numerous contributors. This leads to highly optimized, low-level implementations where even minor alterations can trigger cascading effects. Additionally, traditional bug descriptions in these environments often take the form of raw crash reports and stack traces, which are typically devoid of guiding natural language hints. As a result, diagnosing and repairing issues in such code requires a deep, contextual understanding. This demands not only a grasp of the code’s current logic but also an awareness of its past modifications and global design constraints. Automating such diagnosis and repair has remained elusive, as it requires extensive reasoning that most coding agents are not equipped to perform.
Limitations of Existing Coding Agents for System-Level Crashes
Popular coding agents, such as SWE-agent and OpenHands, leverage large language models (LLMs) for automated bug fixing. However, they primarily focus on smaller, application-level codebases. These agents generally rely on structured issue descriptions provided by humans to narrow their search and propose solutions. Tools such as AutoCodeRover explore the codebase using syntax-based techniques. They are often limited to specific languages like Python and avoid system-level intricacies. Moreover, none of these methods incorporates code evolution insights from commit histories, a vital component when handling legacy bugs in large-scale codebases. While some use heuristics for code navigation or edit generation, their inability to reason deeply across the codebase and consider historical context limits their effectiveness in resolving complex, system-level crashes.
Code Researcher: A Deep Research Agent from Microsoft
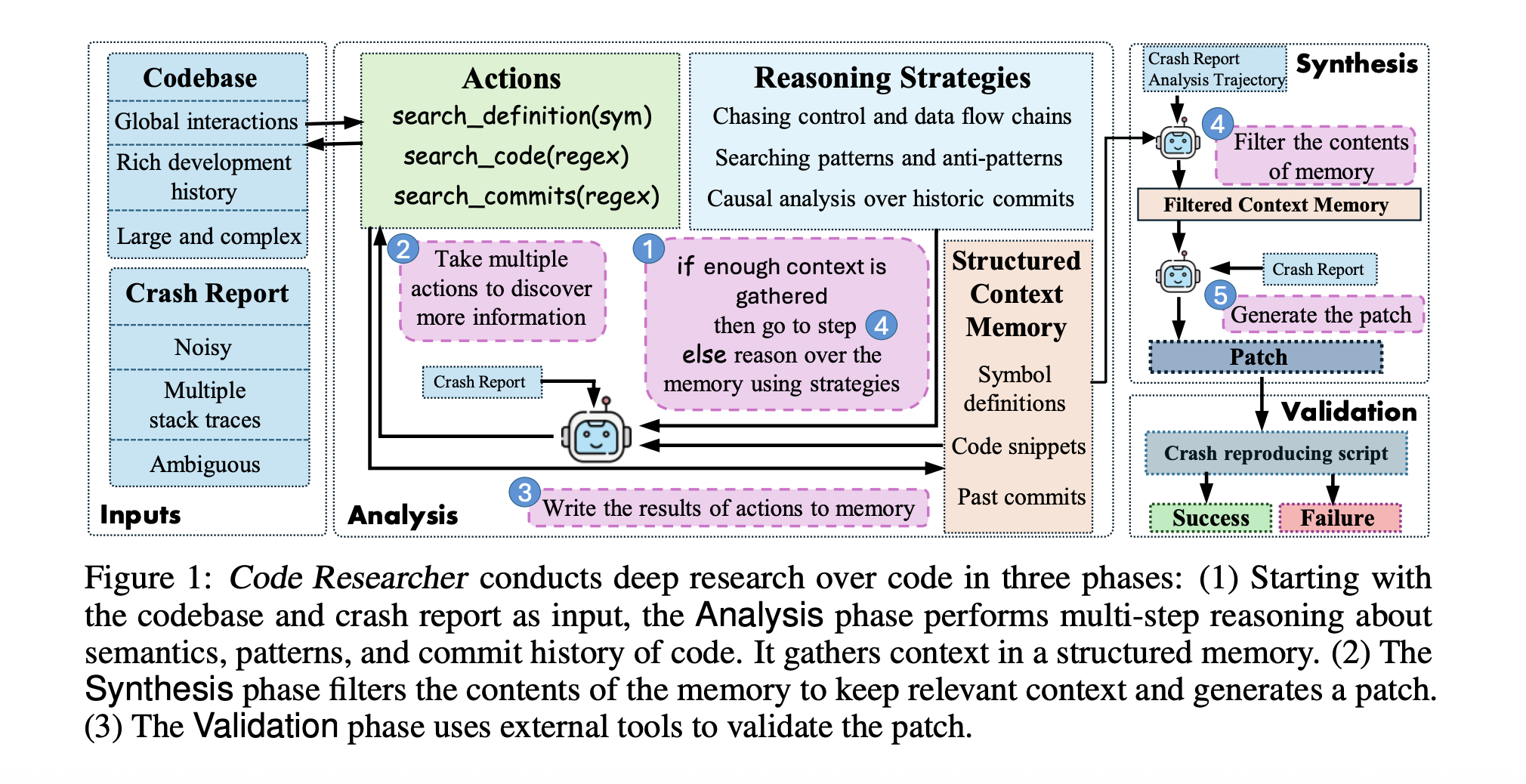
Researchers at Microsoft Research introduced Code Researcher, a deep research agent engineered specifically for system-level code debugging. Unlike prior tools, this agent does not rely on predefined knowledge of buggy files and operates in a fully unassisted mode. It was tested on a Linux kernel crash benchmark and a multimedia software project to assess its generalizability. Code Researcher was designed to execute a multi-phase strategy. First, it analyzes the crash context using various exploratory actions, such as symbol definition lookups and pattern searches. Second, it synthesizes patch solutions based on accumulated evidence. Finally, it validates these patches using automated testing mechanisms. The agent utilizes tools to explore code semantics, identify function flows, and analyze commit histories. This is a critical innovation previously absent in other systems. Through this structured process, the agent operates not only as a bug fixer but also as an autonomous researcher. It collects data and forms hypotheses before intervening in the codebase.
Three-Phase Architecture: Analysis, Synthesis, and Validation
The functioning of Code Researcher is broken down into three defined phases: Analysis, Synthesis, and Validation. In the Analysis phase, the agent begins by processing the crash report and initiates iterative reasoning steps. Each step includes tool invocations to search symbols, scan for code patterns using regular expressions, and explore historical commit messages and diffs. For instance, the agent might search for a term like `memory leak` across past commits to understand code changes that could have introduced instability. The memory it builds is structured, recording all queries and their results. When it determines that enough relevant context has been collected, it transitions into the Synthesis phase. Here, it filters out unrelated data and generates patches by identifying one or more potentially faulty snippets, even if spread across multiple files. In the final Validation phase, these patches are tested against the original crash scenarios to verify their effectiveness. Only validated solutions are presented for use.

Benchmark Performance on Linux Kernel and FFmpeg
Performance-wise, Code Researcher achieved substantial improvements over its predecessors. When benchmarked against kBenchSyz, a set of 279 Linux kernel crashes generated by the Syzkaller fuzzer, it resolved 58% of crashes using GPT-4o with a 5-trajectory execution budget. In contrast, SWE-agent managed only a 37.5% resolution rate. On average, Code Researcher explored 10 files per trajectory, significantly more than the 1.33 files navigated by the SWE-agent. In a subset of 90 cases where both agents modified all known buggy files, Code Researcher resolved 61.1% of the crashes versus 37.8% by SWE-agent. Moreover, when o1, a reasoning-focused model, was used only in the patch generation step, the resolution rate remained at 58%. This reinforces the conclusion that strong contextual reasoning greatly boosts debugging outcomes. The approach was also tested on FFmpeg, an open-source multimedia project. It successfully generated crash-preventing patches in 7 out of 10 reported crashes, illustrating its applicability beyond kernel code.

Key Technical Takeaways from the Code Researcher Study
- Achieved 58% crash resolution on Linux kernel benchmark versus 37.5% by SWE-agent.
- Explored an average of 10 files per bug, compared to 1.33 files by baseline methods.
- Demonstrated effectiveness even when the agent had to discover buggy files without prior guidance.
- Incorporated novel use of commit history analysis, boosting contextual reasoning.
- Generalized to new domains like FFmpeg, resolving 7 out of 10 reported crashes.
- Used structured memory to retain and filter context for patch generation.
- Demonstrated that deep reasoning agents outperform traditional ones even when given more compute.
- Validated patches with real crash reproducing scripts, ensuring practical effectiveness.
Conclusion: A Step Toward Autonomous System Debugging
In conclusion, this research presents a compelling advancement in automated debugging for large-scale system software. By treating bug resolution as a research problem, requiring exploration, analysis, and hypothesis testing, Code Researcher exemplifies the future of autonomous agents in complex software maintenance. It avoids the pitfalls of previous tools by operating autonomously, thoroughly examining both the current code and its historical evolution, and synthesizing validated solutions. The significant improvements in resolution rates, particularly across unfamiliar projects such as FFmpeg, demonstrate the robustness and scalability of the proposed method. It indicates that software agents can be more than reactive responders; they can function as investigative assistants capable of making intelligent decisions in environments previously thought too complex for automation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

