OpenThoughts: A Scalable Supervised Fine-Tuning SFT Data Curation Pipeline for Reasoning Models


The Growing Complexity of Reasoning Data Curation
Recent reasoning models, such as DeepSeek-R1 and o3, have shown outstanding performance in mathematical, coding, and scientific areas, utilizing post-training techniques like supervised fine-tuning (SFT) and reinforcement learning (RL). However, the complete methodologies behind these frontier reasoning models are not public, which makes research for building reasoning models difficult. While SFT data curation has become a powerful approach for developing strong reasoning capabilities, most existing efforts explore only limited design choices, such as relying solely on human-written questions or single teacher models. Moreover, exploring the extensive design space of various techniques for generating question-answer pairs requires high costs for teacher inference and model training.
Reasoning traces provided by models such as Gemini, QwQ, and DeepSeek-R1 have enabled knowledge distillation techniques to train smaller reasoning models. Projects like OpenR1, OpenMathReasoning, and OpenCodeReasoning collect questions from public forums and competition sites, while Natural Reasoning utilizes pre-training corpora as seed data. Some efforts, such as S1 and LIMO, focus on manually curating small, high-quality datasets of challenging prompts. Other methods, such as DeepMath-103K and Nvidia Nemotron, introduce innovations across data sourcing, filtering, and scaling stages. RL methods, including AceReason and Skywork-OR1, have enhanced reasoning capabilities beyond traditional SFT methods.
OpenThoughts: A Scalable Framework for SFT Dataset Development
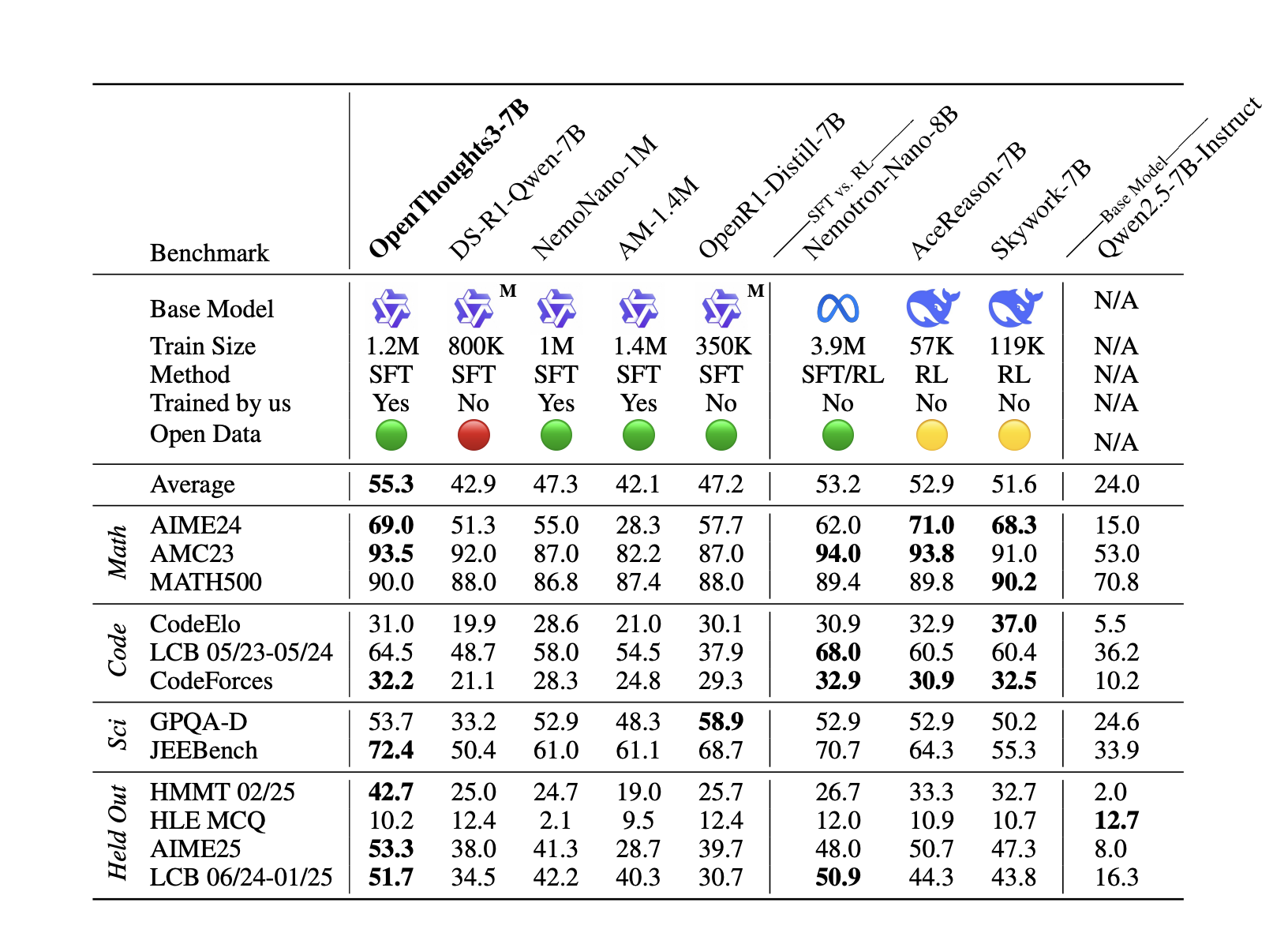
Researchers from Stanford University, the University of Washington, BespokeLabs.ai, Toyota Research Institute, UC Berkeley, and 12 additional organizations have proposed OpenThoughts, a new SOTA open reasoning data recipe. OpenThoughts uses a progressive approach across three iterations: OpenThoughts-114K scales the Sky-T1 pipeline with automated verification, OpenThoughts2-1M enhances data scale through augmented question diversity and synthetic generation strategies, and OpenThoughts3-1.2M incorporates findings from over 1,000 ablation experiments to develop a simple, scalable, and high-performing data curation pipeline. Moreover, the model OpenThinker3-7B achieves state-of-the-art performance among open-data models at the 7B scale.
The OpenThoughts3-1.2M is built by ablating each pipeline component independently while maintaining constant conditions across other stages, generating 31,600 data points per strategy and fine-tuning Qwen2.5-7B-Instruct on each resulting dataset. The goal during training is to create the best dataset of question-response pairs for SFT reasoning. Evaluation occurs across eight reasoning benchmarks across mathematics (AIME24, AMC23, MATH500), coding (CodeElo, CodeForces, LiveCodeBench), and science (GPQA Diamond, JEEBench). The experimental design includes a rigorous decontamination process to remove high-similarity samples and maintains a held-out benchmark set for generalization testing. Evalchemy serves as the primary evaluation tool, ensuring consistent evaluation protocols.
Evaluation Insights and Benchmark Performance
The OpenThoughts pipeline evaluation reveals key insights across question sourcing, mixing, filtering, answer filtering, and the teacher model. Question sourcing experiments show that CodeGolf and competitive coding questions achieve the highest performance for code tasks (25.3-27.5 average scores), while LLM-generated and human-written questions excel in mathematics (58.8-58.5 scores), and physics StackExchange questions with chemistry textbook extractions perform best in science (43.2-45.3 scores). Mixing question shows that combining multiple question sources degrades performance, with optimal results of 5% accuracy improvements over diverse mixing strategies. In the teacher model, QwQ-32B outperforms DeepSeek-R1 in knowledge distillation, achieving an accuracy improvement of 1.9-2.6%.
In conclusion, researchers present the OpenThoughts project, showing that systematic experimentation can significantly advance SFT data curation for reasoning models. Researchers developed OpenThoughts3-1.2M, a state-of-the-art open-data reasoning dataset across science, mathematics, and coding domains. The resulting OpenThinker3-7B model achieves superior performance among open-data reasoning models at its scale. However, several limitations remain unexplored, including RL approaches, staged fine-tuning, and curriculum learning strategies. Future research directions include investigating cross-domain transfer effects when optimizing individual domains versus overall performance, and understanding the scaling dynamics as student models approach teacher capabilities.
Check out the Paper, Project Page and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 99k+ ML SubReddit and Subscribe to our Newsletter.

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.

