Stability AI Introduces Adversarial Relativistic-Contrastive (ARC) Post-Training and Stable Audio Open Small: A Distillation-Free Breakthrough for Fast, Diverse, and Efficient Text-to-Audio Generation Across Devices


Text-to-audio generation has emerged as a transformative approach for synthesizing sound directly from textual prompts, offering practical use in music production, gaming, and virtual experiences. Under the hood, these models typically employ Gaussian flow-based techniques such as diffusion or rectified flows. These methods model the incremental steps that transition from random noise to structured audio. While highly effective in producing high-quality soundscapes, the slow inference speeds have posed a barrier to real-time interactivity. It is particularly limiting when creative users expect an instrument-like responsiveness from these tools.
Latency is the primary issue with these systems. Current text-to-audio models can take several seconds or even minutes to generate a few seconds of audio. The core bottleneck lies in their step-based inference architecture, requiring between 50 and 100 iterations per output. Previous acceleration strategies focus on distillation methods where smaller models are trained under the supervision of larger teacher models to replicate multi-step inference in fewer steps. However, these distillation methods are computationally expensive. They demand large-scale storage for intermediate training outputs or require simultaneous operation of several models in memory, which hinders their adoption, especially on mobile or edge devices. Also, such methods often sacrifice output diversity and introduce over-saturation artifacts.
While a few adversarial post-training methods have been attempted to bypass the cost of distillation, their success has been limited. Most existing implementations rely on partial distillation for initialization or do not scale well to complex audio synthesis. Also, audio applications have seen fewer fully adversarial solutions. Tools like Presto integrate adversarial objectives but still depend on teacher models and CFG-based training for prompt adherence, which restricts their generative diversity.
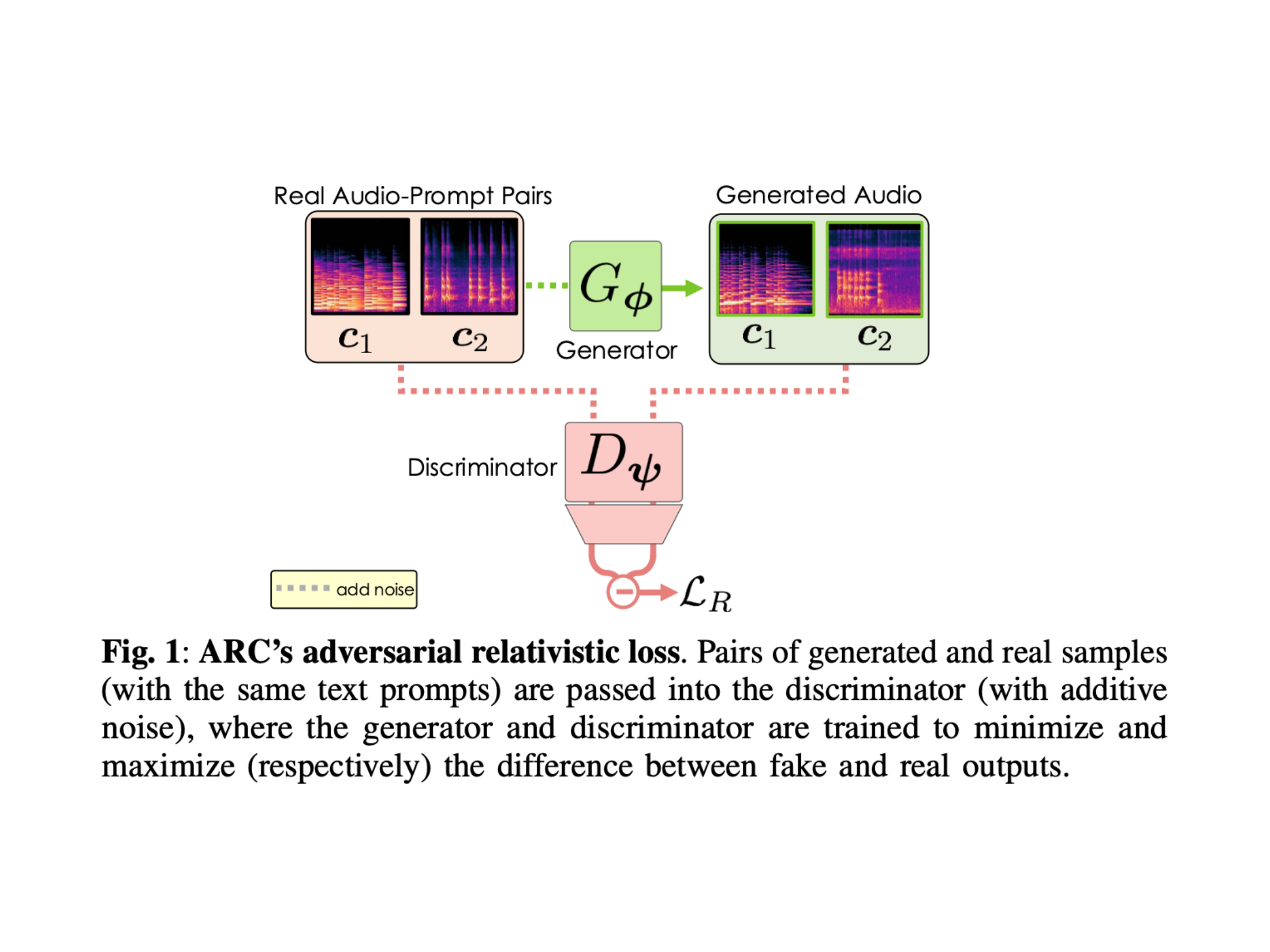
Researchers from UC San Diego, Stability AI, and Arm introduced Adversarial Relativistic-Contrastive (ARC) post-training. This approach sidesteps the need for teacher models, distillation, or classifier-free guidance. Instead, ARC enhances an existing pre-trained rectified flow generator by integrating two novel training objectives: a relativistic adversarial loss and a contrastive discriminator loss. These help the generator produce high-fidelity audio in fewer steps while maintaining strong alignment with text prompts. When paired with the Stable Audio Open (SAO) framework, the result was a system capable of generating 12 seconds of 44.1 kHz stereo audio in only 75 milliseconds on an H100 GPU and around 7 seconds on mobile devices.
With ARC methodology, they introduced Stable Audio Open Small, a compact and efficient version of SAO tailored for resource-constrained environments. This model contains 497 million parameters and uses an architecture built on a latent diffusion transformer. It consists of three main components: a waveform-compressing autoencoder, a T5-based text embedding system for semantic conditioning, and a DiT (Diffusion Transformer) that operates within the latent space of the autoencoder. Stable Audio Open Small can generate stereo audio up to 11 seconds long at 44.1 kHz. It is designed to be deployed using the ‘stable-audio-tools’ library and supports ping-pong sampling, enabling efficient few-step generation. The model demonstrated exceptional inference efficiency, achieving generation speeds of under 7 seconds on a Vivo X200 Pro phone after applying dynamic Int8 quantization, which also cut RAM usage from 6.5GB to 3.6 GB. This makes it especially viable for on-device creative applications like mobile audio tools and embedded systems.
The ARC training approach involves replacing the traditional L2 loss with an adversarial formulation where generated and real samples, paired with identical prompts, are evaluated by a discriminator trained to distinguish between them. A contrastive objective teaches the discriminator to rank accurate audio-text pairs higher than mismatched ones to improve prompt relevance. These paired objectives eliminate the need for CFG while achieving better prompt adherence. Also, ARC adopts ping-pong sampling to refine the audio output through alternating denoising and re-noising cycles, reducing inference steps without compromising quality.
ARC’s performance was evaluated extensively. In objective tests, it achieved an FDopenl3 score of 84.43, a KLpasst score of 2.24, and a CLAP score of 0.27, indicating balanced quality and semantic precision. Diversity was notably strong, with a CLAP Conditional Diversity Score (CCDS) of 0.41. Real-Time Factor reached 156.42, reflecting outstanding generation speed, while GPU memory usage remained at a practical 4.06 GB. Subjectively, ARC scored 4.4 for diversity, 4.2 for quality, and 4.2 for prompt adherence in human evaluations involving 14 participants. Unlike distillation-based models like Presto, which scored higher on quality but dropped to 2.7 on diversity, ARC presented a more balanced and practical solution.

Several Key Takeaways from the Research by Stability AI on Adversarial Relativistic-Contrastive (ARC) post-training and Stable Audio Open Small include:
- ARC post-training avoids distillation and CFG, relying on adversarial and contrastive losses.
- ARC generates 12s of 44.1 kHz stereo audio in 75ms on H100 and 7s on mobile CPUs.
- It achieves 0.41 CLAP Conditional Diversity Score, the highest among tested models.
- Subjective scores: 4.4 (diversity), 4.2 (quality), and 4.2 (prompt adherence).
- Ping-pong sampling enables few-step inference while refining output quality.
- Stable Audio Open Small offers 497M parameters, supports 8-step generation, and is compatible with mobile deployments.
- On Vivo X200 Pro, inference latency dropped from 15.3s to 6.6s with half the memory.
- ARC and SAO Small provide real-time solutions for music, games, and creative tools.
In conclusion, the combination of ARC post-training and Stable Audio Open Small eliminates the reliance on resource-intensive distillation and classifier-free guidance, enabling researchers to deliver a streamlined adversarial framework that accelerates inference without compromising output quality or prompt adherence. ARC enables fast, diverse, and semantically rich audio synthesis in high-performance and mobile environments. With Stable Audio Open Small optimized for lightweight deployment, this research lays the groundwork for integrating responsive, generative audio tools into everyday creative workflows, from professional sound design to real-time applications on edge devices.
Check out the Paper, GitHub Page and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 90k+ ML SubReddit.
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

