This AI Paper Introduces Diversified DPO and ORPO: Post-Training Methods to Boost Output Diversity in Creative Writing with LLMs
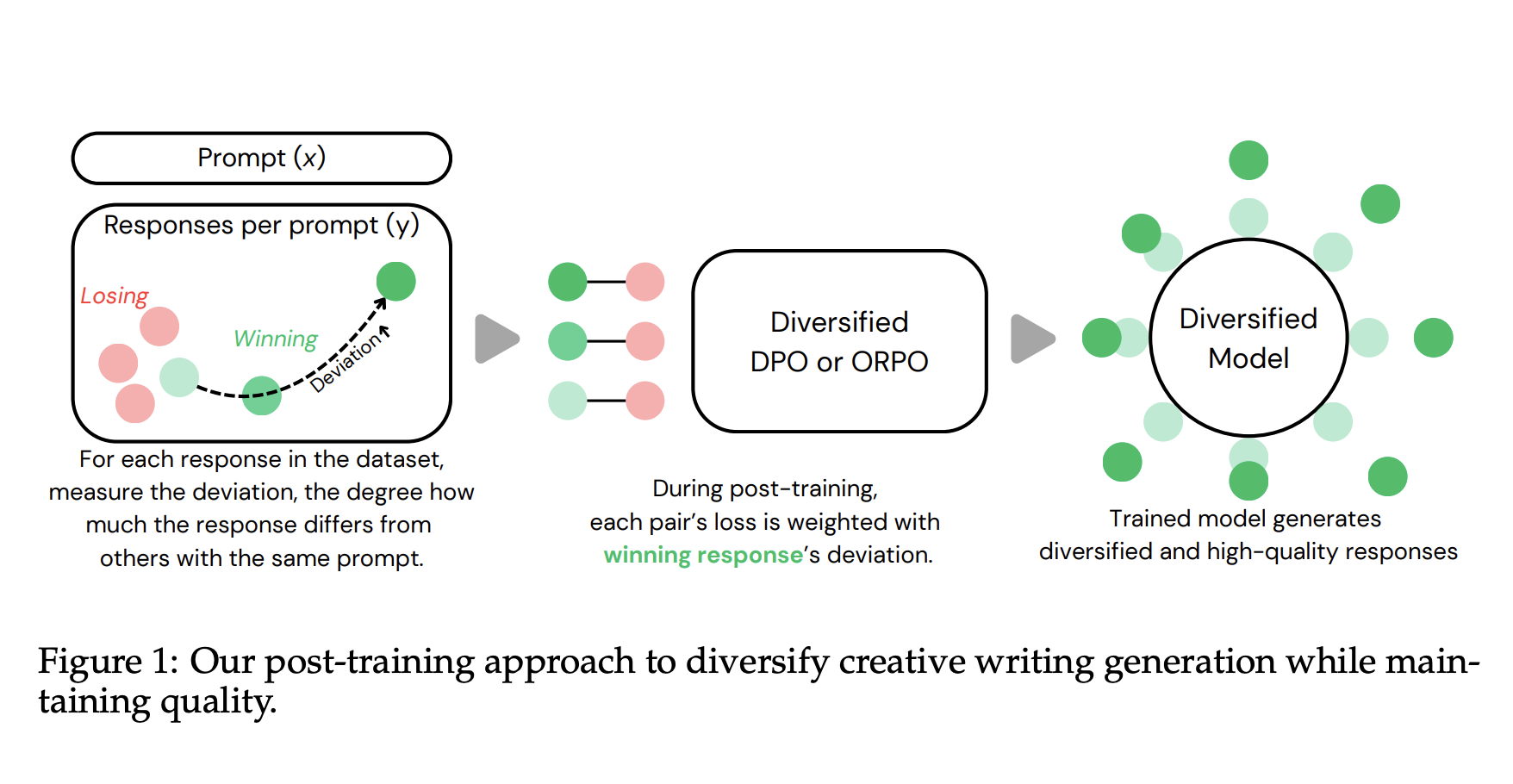


Creative writing is a domain that thrives on diversity and imagination. Unlike fact-based or task-specific writing, where a single correct output may exist, creative writing involves numerous valid responses to a prompt. Stories, poems, and narratives can branch in countless directions, each with stylistic flavor and meaning. This inherent open-mindedness makes creative writing a prime challenge for AI systems, which need to maintain narrative coherence while producing novel and distinct outputs.
The core issue lies in how large language models are refined after their initial training. Post-training methods often emphasize quality improvements by aligning responses with user preferences or maximizing reward scores. However, these adjustments inadvertently cause the models to produce responses that are too similar across prompts. In creative settings, this leads to a noticeable drop in output diversity. A lack of variation limits the expressive power of the model, resulting in uniform storylines or similar sentence constructions even when prompts are vastly different.
Earlier solutions attempted to address this by tweaking decoding methods or prompt strategies. Researchers used sampling temperature adjustment, top-k or top-p filtering, or iterative prompting to introduce randomness. Some explored methods, such as beam search modifications or self-critiquing, to encourage alternative responses. While these helped diversify outputs, they often came with a cost—sacrificing overall response quality, increasing generation time, or introducing inconsistencies in tone and grammar. More crucially, they did not adopt the model’s core training process to learn from diverse samples.
Researchers from Midjourney and New York University proposed a novel adjustment during the post-training phase. They introduced “Diversified DPO” and “Diversified ORPO”—enhanced versions of two popular preference-based optimization techniques. Their innovation was incorporating a deviation score, quantifying how much a training example differs from others responding to the same prompt. Rare and diverse responses are given more importance during learning by using this score to weight training losses. The researchers specifically implemented these strategies on large models like Meta’s Llama-3.1-8B and Mistral-7B using parameter-efficient fine-tuning via LoRA.

In this approach, deviation acts as a learning signal. For every training pair of a better and worse response to a prompt, the deviation of the better response is computed using both semantic and stylistic embeddings. These embeddings measure not only content differences but also stylistic uniqueness between responses. The resulting score then influences how much that training pair contributes to the model’s weight updates. This method increases the likelihood that the model generates distinct yet high-quality outputs. The training used over 400,000 prompt-response pairs with Reddit upvotes as quality signals and introduced mixing methods to effectively balance semantic and style deviations.
Quantitative results demonstrated the success of the proposed method. The best-performing model, Llama-3.1-8B with Diversified DPO using semantic and style deviation (DDPO-both), achieved nearly the same reward score as GPT-4o while significantly outperforming it in diversity. Specifically, the model had semantic diversity approaching that of the human-crafted reference dataset and style diversity slightly below it. In head-to-head human evaluations, 68% of reviewers preferred DDPO-both’s outputs over GPT-4o’s for quality, and 100% chose them as more diverse. Compared to the baseline DPO, DDPO-both still came out ahead, selected 50% of the time for quality and 62% for diversity. When fewer responses per prompt were available during training, slight drops in reward scores were mitigated using a minimum deviation threshold or sampling higher-quality responses.

This research highlighted a compelling solution to the diversity-quality trade-off in AI-generated creative writing. By emphasizing deviation in training, the researchers enabled models to value uniqueness without compromising coherence. The outcome is a model that delivers richer and more varied storytelling, marking a meaningful step forward in creative AI development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
